DR;TL (“Ez dut irakurri; luzeegia” bertsioa)
NongoEuskara esperimentua sortu dut. Horretarako, datuak bilatu, fastText saikapen edo embedding eredua entrenatu, eta demo webgunetxo hau sortu dut. WebAssembly erabiliz, sortutako eredu hauek nabigatzailean exekutatzen dira.
Azalpen luzea
Badakigu hizkuntza eredu handiak (LLM) denetik egiteko gai direla. Nahiz eta, hasiera batean, ez ziren horretarako sortu, gaur egun gai dira programatzeko, itzulketak egiteko, audioa transkribatzeko, testu luzeak laburtzeko, etabar luze bat. Batzuetan, ordea, soluzio egokiena ez da beti LLM bat erabiltzea izango. Adibidez, itzulpen azkarrak eta sinpleak egiteko, badira LLMak baino itzultzaile neuronal arinagoak, baliabide gutxiago behar dituztenak.
Hizkuntza identifikatzaileekin antzerakoa gertatzen da. Testu bat emanda, zein hizkuntza den jakiteko, ez dugu LLM baten beharrik. Hizkuntzaren Identifikazioa horretaz arduratzen da hain zuzen. fastText (Meta AI) bezalako embedding ereduak horretarako balio dezakete besteak beste. Badaude eskuragarri entrenatutako fastText ereduak, baliabide gutxirekin, hizkuntza identifikatzeko gai direnak.
Eta euskalkiak identifikatzeko?
Galdera honi erantzun nahian, ideiarik izan gabe, eskura ditugun aukerak aztertzen hasi nintzen. Nahiz eta ez dudan aurkitu ezer honen inguruan argitaratuta, pentsatzen dut etxeko lan edo gradu amaierako lanetan, ikasle batek baina gehiagok sortuko zituela euskalkiak identifikatzeko sistemak (sare neuronalak edo bestela oinarrizko erregela bidezkoak).
Azkenean, fastText liburutegia erabiliz euskalkiak identifikatzeko sailkapen-ereduak sortu ditut. Eredu hauek edozein gailu xumeetan exekutatu daitezke. Hare gehiago, eredua entrenatzeko ere ez dut GPU edo ordenagailu berezirik behar izan.
Lan mardulena, datuak eskuratzea izan da. Horretarako, bereziki eskertu nahiko nituzke erabili ditudan iturriak: Ahotsak.eus, Euskalkien Katalogoa (HiTZ), Klasikoak (Armiarma) eta desagertutako SÜ AZIA.
Autoresearch
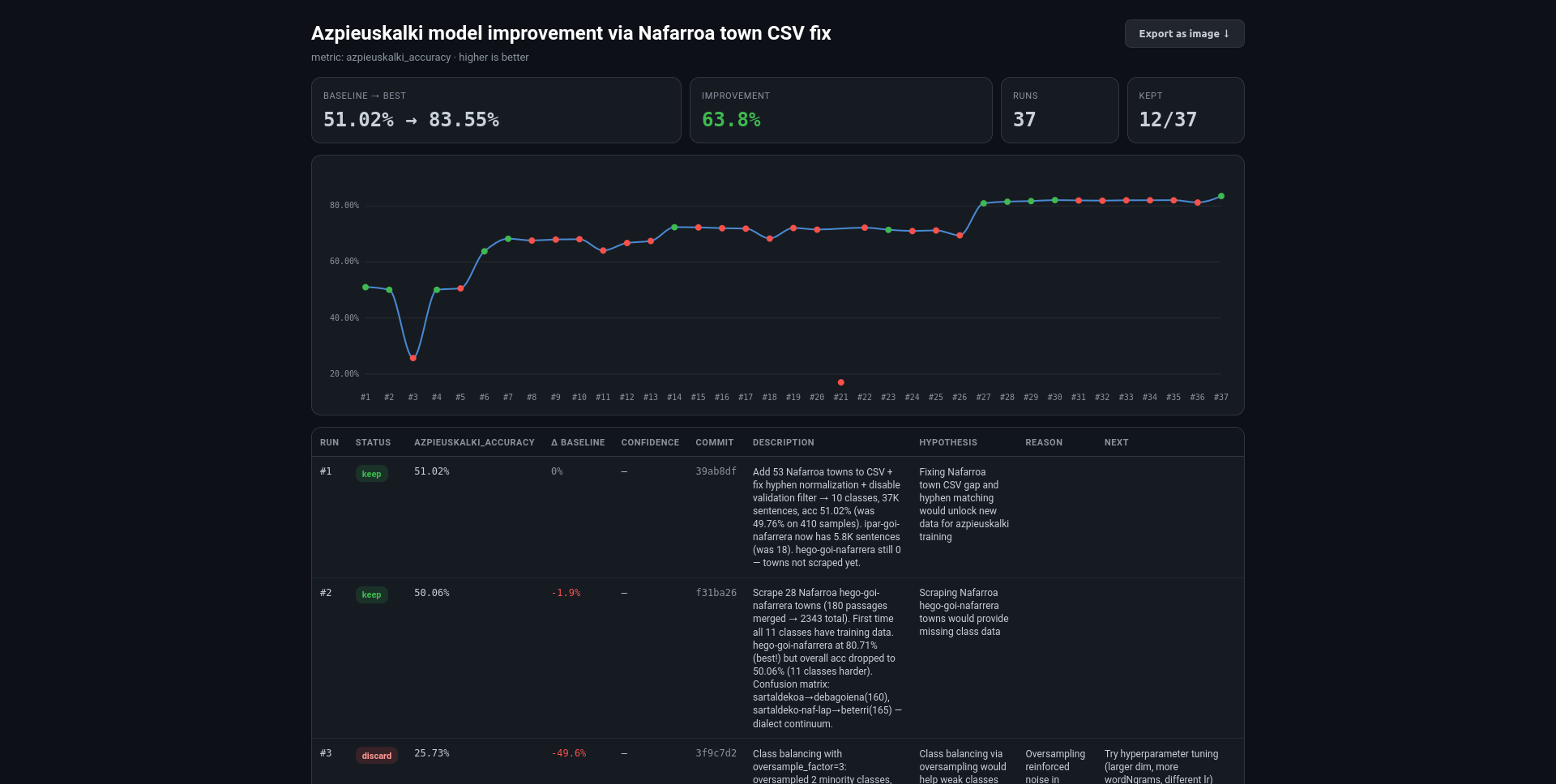
Gauza da, lehen esan bezala, ez naizela aditua esparru honetan. Ereduak entrenatzea, emaitzak interpretatzea, etab. lan handia da eta horretarako ezagutza espezifikoak behar dira. Lan hau errezteko pi-autoresearch erabili dut. Entrenamenduak eta hauen emaitzak optimizatzeko bereziki sortutako agente-extentsio bat da.
Modu laburrean azalduta: entrenamendu hiperparametro edo konfigurazio ezberdinak probatzen joango da, beti ere aurretik jasotako emaitzen interpretazioaren baitan, behin eta berriro (nekaezina da). Emaitzak hobetzea lortu badu, aldaketak gordeko ditu. Kaxkarragoak badira, ezeztatzen dira. Horrela, behin eta berriro, 30 bat saiakera egin eta emaitzak ikaragarri pila hobetu dituela ikusi dut.
Ondorio gisa: emaitzak kuantitatiboki neurtzea posible denean, interesgarria izan daiteken fluxua iruditu zait. Kasu oso zehatzetarako soilik. Bestalde, kontuz gainbegiratu beharrekoa, bere buruari tranpak egiten hastea oso posible dela ere konturatu naiz.
Nongo euskara ?
Eredu hauekin zer egin, eta demo txukun bat egin behar zela pentsatu nuen. Web estatiko baten bidez, ahal bada, mantenua errezteko eta dohainezko baliabideak aprobetxatzeko.
Erabiltzaileak testu bat sartu, identifikatu eta Euskal Herriko mapan azpieuskalkia eta dagokion eskualde multzoa azpimarratzea nahi nuen. Spoiler: nola ez, frontend zati hau izan da gehien kostatu zaidan zatia! Entrenamendua baina gehiago!
Hau egiteko, WebAssembly (WASM) bidez exekutatu behar izan dut eredua, aldez aurretik kuantizatuta (konprimatuta). Berirro ere ondorio berdina: WASM ikaragarria da horrelako gauzetarako! Zerbitzaririk gabe, datuak inora bidali gabe, erabiltzaileok gure nabigatzaileetan punta-puntako aplikazio edo adimen artifizialeko ereduak exekutatu ditzakegu.