TL;DR
I’ve created an experiment called NongoEuskara. To do this, I gathered data, trained a fastText classification/embedding model, and built this little demo website. Using WebAssembly, these models run directly in the browser.
The long explanation
We know that large language models (LLMs) are capable of doing pretty much everything. Even though they weren’t originally designed for it, today they can program, translate, transcribe audio, summarize long texts, and a long etcetera. Sometimes, however, the best solution isn’t always using an LLM. For example, for quick and simple translations, there are lighter neural translators that require far fewer resources than LLMs.
The same goes for language identification. Given a text, to know what language it is, we don’t need an LLM. Language Identification is what deals with that. Embedding models like fastText (Meta AI) can serve that purpose, among others. There are pre-trained fastText models available that, with few resources, are capable of identifying languages.
And what about identifying Basque dialects?
Trying to answer this question, with no clear idea where to start, I began looking into the options at hand. Even though I haven’t found anything published on this topic, I imagine that in school projects or final degree theses, more than one student will have created systems for identifying Basque dialects (neural networks or basic rule-based ones).
In the end, I used the fastText library to create classification models for identifying Basque dialects. These models can run on any modest device. What’s more, I didn’t even need a GPU or special computer to train the model.
The heaviest work was gathering the data. I’d especially like to thank the sources I used: Ahotsak.eus, Catalog of Basque Dialects (HiTZ), Klasikoak (Armiarma), and the now-defunct SÜ AZIA.
Autoresearch
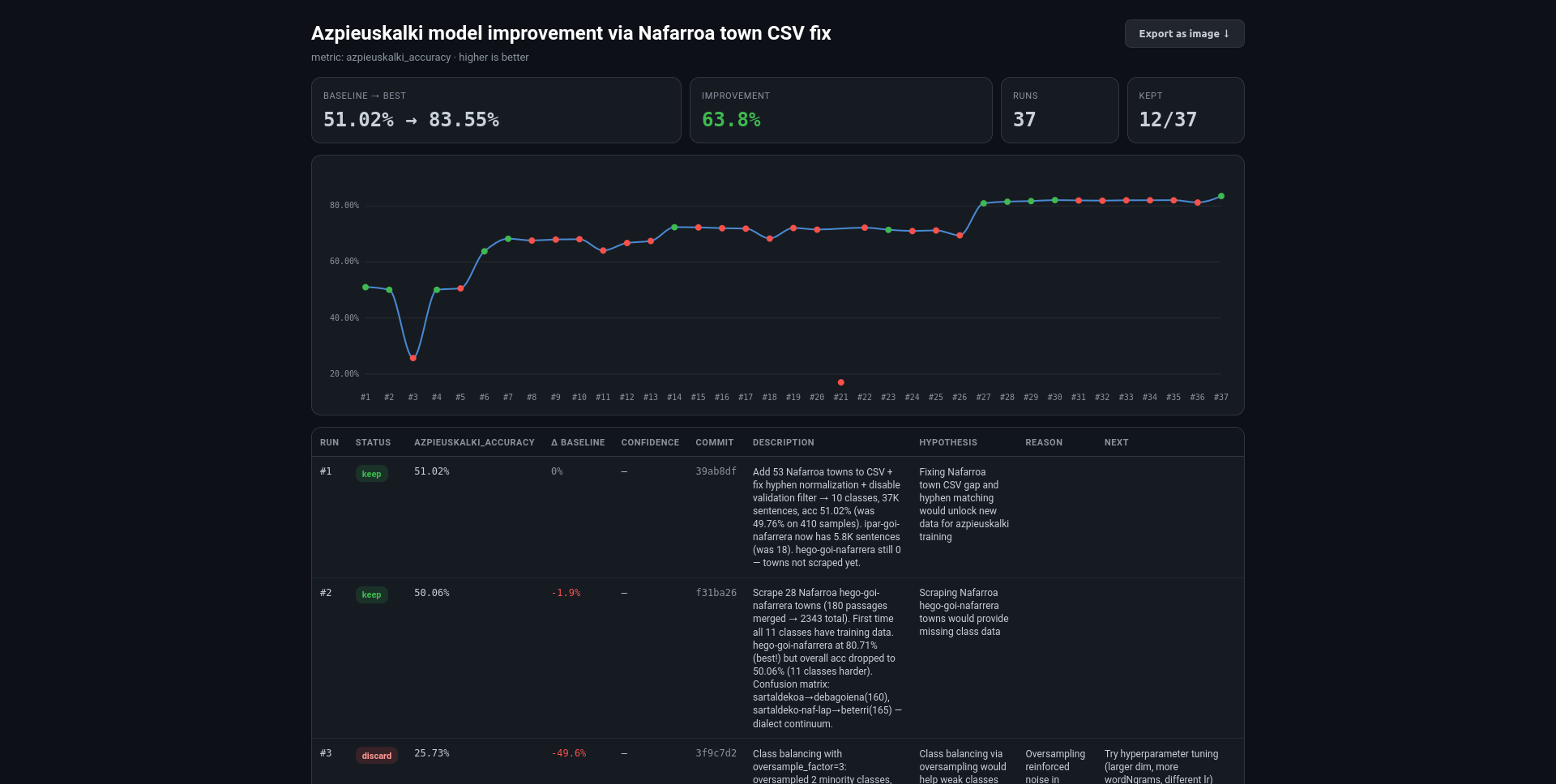
The thing is, as I mentioned before, I’m not an expert in this field. Training models, interpreting results, etc. is a lot of work and requires specialized knowledge. To make this easier, I used pi-autoresearch. It’s an agent extension specifically designed to optimize training runs and their results.
In a nutshell: it tries out different training hyperparameters or configurations, always based on the interpretation of previously gathered results, over and over (it’s tireless). If it manages to improve the results, it saves the changes. If they’re worse, they’re discarded. This way, after around 30 attempts, I saw the results improve enormously.
In conclusion: when it’s possible to measure results quantitatively, this seems like an interesting workflow. Only for very specific cases though. On the other hand, it needs careful supervision — I also realized it’s very easy for it to start cheating itself.
Nongo euskara? (Which Basque?)
With these models in hand, I thought, “what do I do with them?” — and decided I needed to build a nice demo. Preferably via a static website, for easy maintenance and to take advantage of free resources.
I wanted users to enter a text, have it identified, and then highlight the sub-dialect and corresponding region on a map of the Basque Country. Spoiler: of course, the frontend part was the most painful bit! Even more than the training!
To do this, I had to run the model via WebAssembly (WASM), previously quantized (compressed). Same conclusion again: WASM is amazing for this kind of thing! Without a server, without sending data anywhere, we as users can run cutting-edge applications or AI models right in our browsers.